
티스토리 뷰
주피터 노트북을 사용할 것이다.
설치
pip install jupyter notebook
pip install requests bs4 matplotlib seaborn
pip install openpyxl
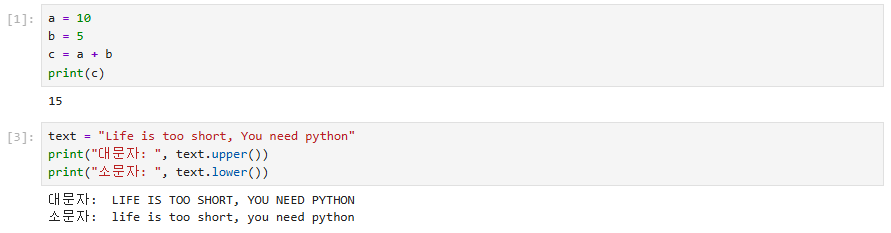
복습: lower, upper 메서드 사용
strip()메서드 사용법
rstrip() or lstrip() or strip()
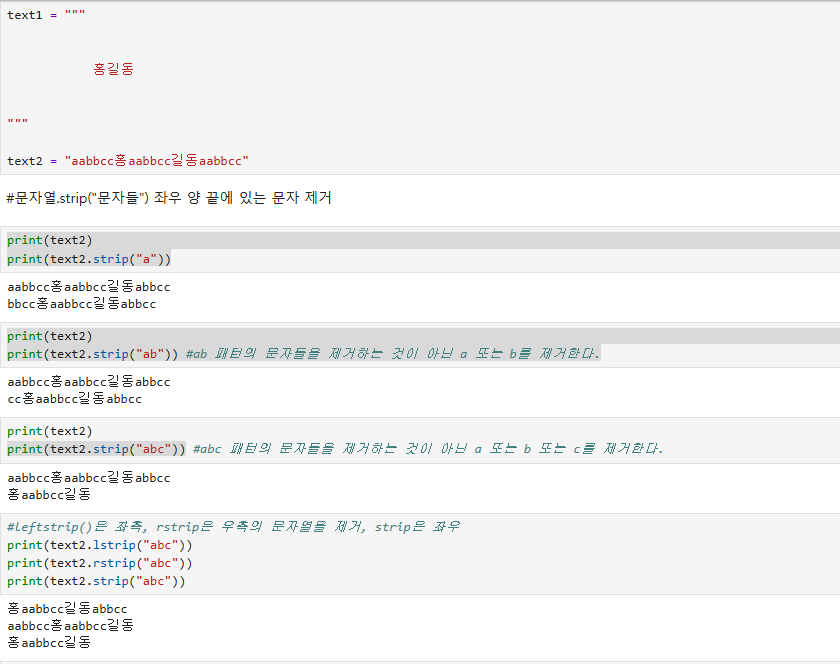
본래 기본적으로 공백문자들을 제거하기 위해서 만들어진 메서드임

strip() 메서드로 좌, 우의 공백문자를 제거한 모습이다.

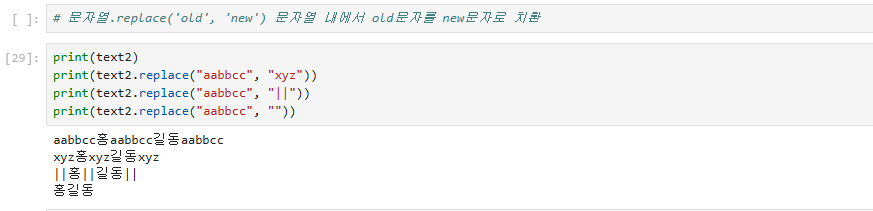
문자열의 패턴을 new 패턴으로 치환하는 명령어
전체 문자열을 지정한 구분자로 구분하고 목록화하는 메서드
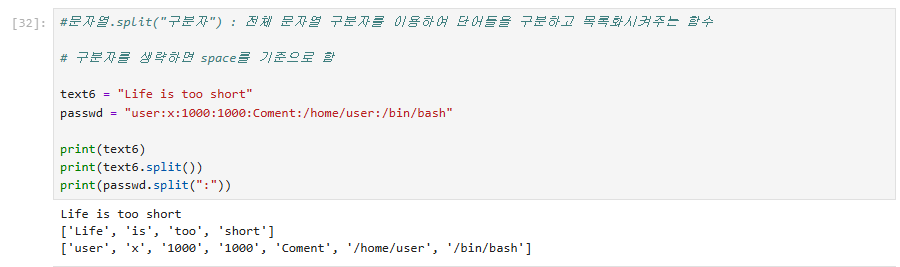
정렬에 사용되는 메서드지만 보통 출력이 나오면 실제 값에 적용되지 않을 가능성이 높다.
행동에 대한 조회의 개념인지 실제 값이 적용되는 개념인지 각 메서드마다 적응해가며 배워보자

리스트 자료형
[]안에 정의된 내용은 리스트 자료형이다.

리스트 자료형을 사용하면 보다 동적인 코드를 쓸 수 있다.

문자열과 같은 개념으로 인덱싱과 슬라이싱을 적용할 수 있다.

같은 레이블의 데이터의 리스트라면 순서를 다르게 하면 원하지 않는 값이 나올 수 있다.
리스트 순서를 잘 지켜주자

인덱싱과 슬라이싱을 하여 원하는 값을 출력한 모습이다.
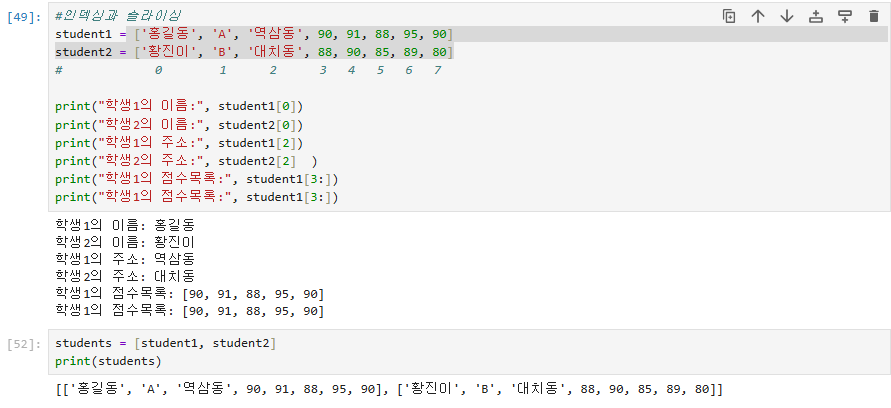
리스트에서 리스트 안에 리스트가 있는 식이라면 타 언어의 2차원 배열과 같은 인덱싱을 해줘야 한다.
리스트[열의 인덱싱][행의 인덱싱]으로 원하는 인자를 찾을 수 있다.
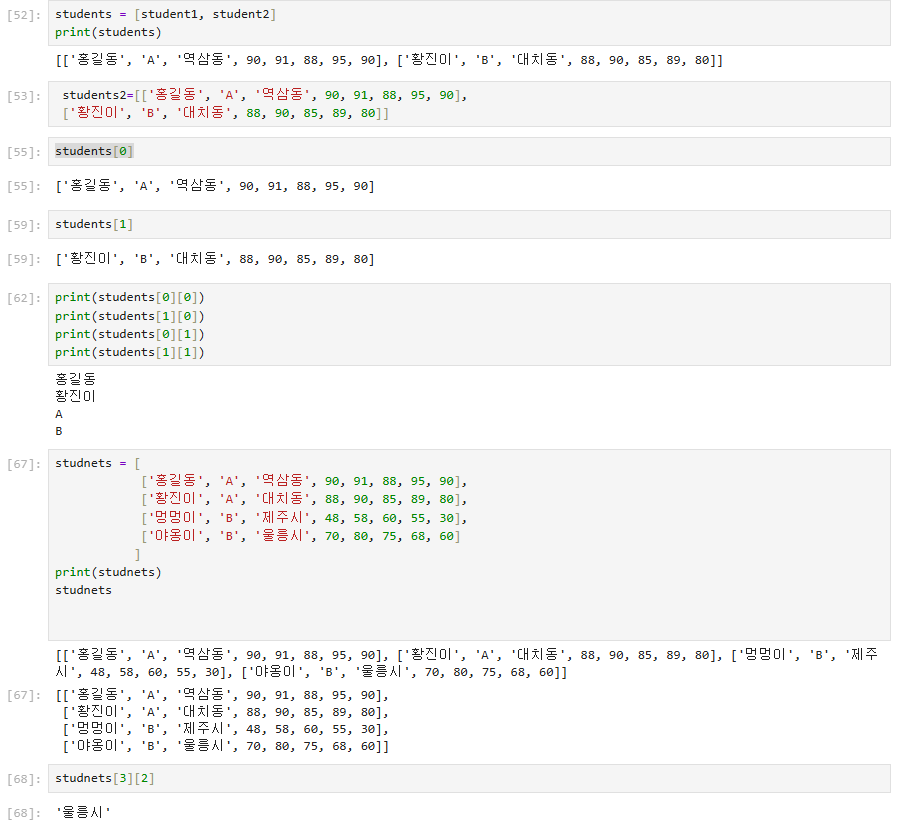
이런 3차원 리스트도 인덱싱할 수 있고 3차원 배열의 원소값이 문자열이라면 문자 배열에 대한 인덱싱이 추가로 가능하다.
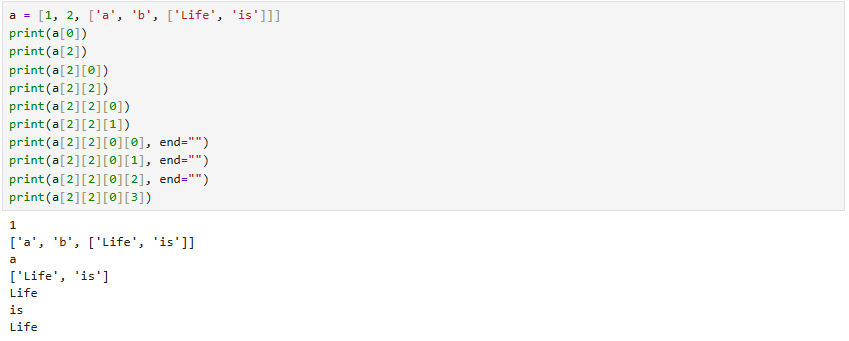
문자열과 비슷한 방식으로 연산 되지만 목록의 단위로 연산이 되는 것을 확인해야 한다.

리스트의 길이를 확인 가능한 len 메서드
리스트 인덱싱을 하는 모습이고, 길이를 변수에 저장해서 슬라이싱하는데 사용하면 동적인 코드를 짤 수 있다.
슬라이싱의 결과는 반드시 목록으로 나온다. (원소가 하나만 출력되어도)

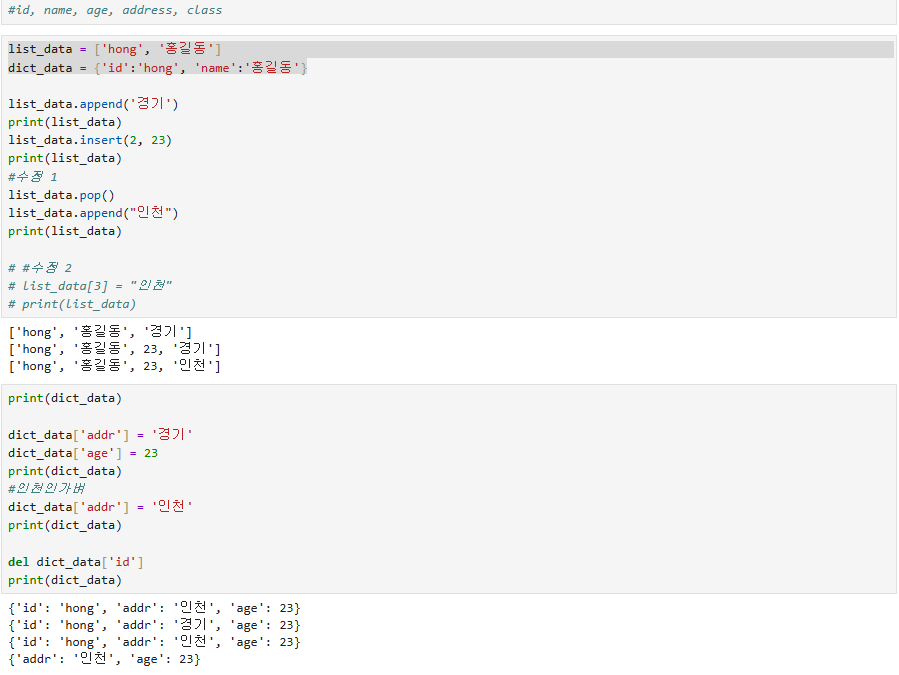
목록의 원소를 마지막에 추가하는 .append() 메서드와 위치를 지정하여 추가하는 .insert() 메서드를 확인해보자

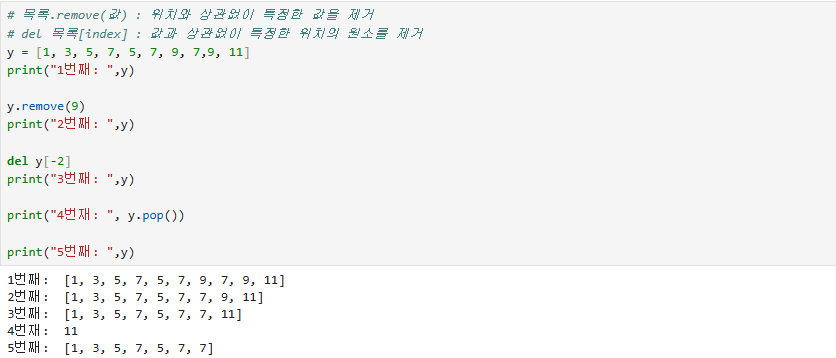
목록의 특정한 값을 제거하는 .remove() 메서드와 특정한 위치의 원소를 제거하는 del list[index]가 있다.
리스트 a의 길이를 출력하는 코드이고
만약 3번째 인덱스가 될 것이라 해서 a[3]로 코드를 짜면 out of range로 인덱스의 범위를 벗어난 것이다.

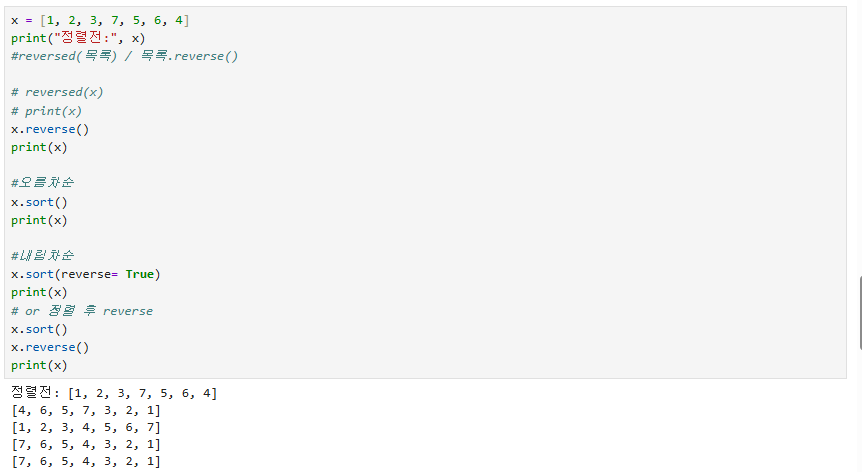
sorted()와 x.sort()는 실제 L 벨류에 값이 들어가는지 아닌지에 차이가 있다.

정렬 오름차순 내림차순, reverse로 목록 뒤집기 등
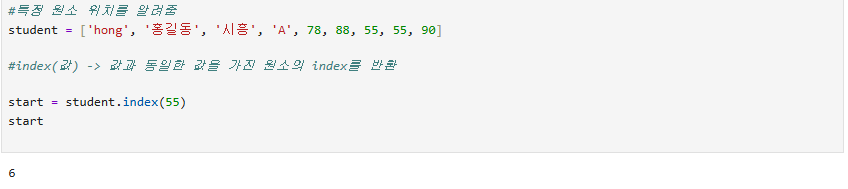
특정 원소의 인덱스 값을 찾아주는 메서드
pop() 메서드 없이 같은 작업을 구현하려면 출력과 del의 동작이 있어야 함

python의 random 모듈을 불러와서 사용하는 모습
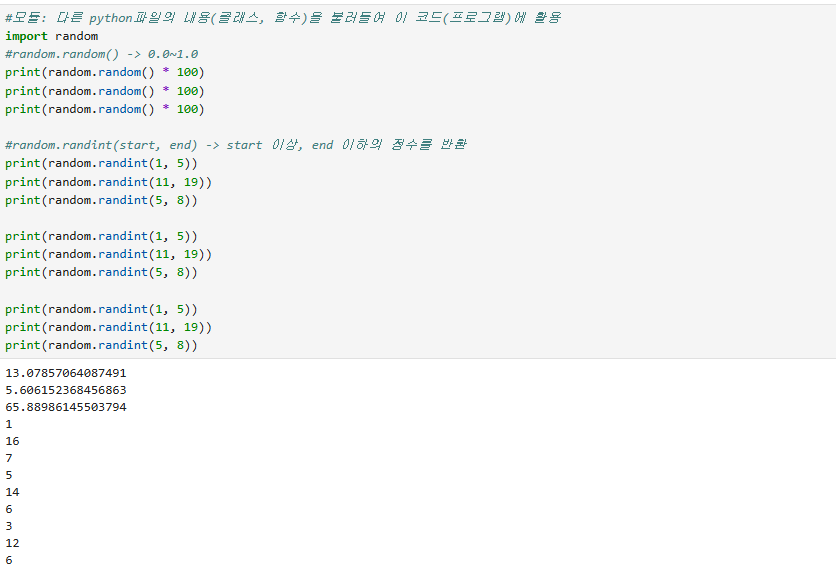
랜덤으로 번호를 뽑고 뽑히면 목록에서 제거되는 코드

리스트에 해당 패턴이 몇 개 있는지 확인

extend는 메모리 시작 주소가 같은 것을 보면 변수를 새로 만들어서 사용하지 않는다는 것을 알 수 있다.
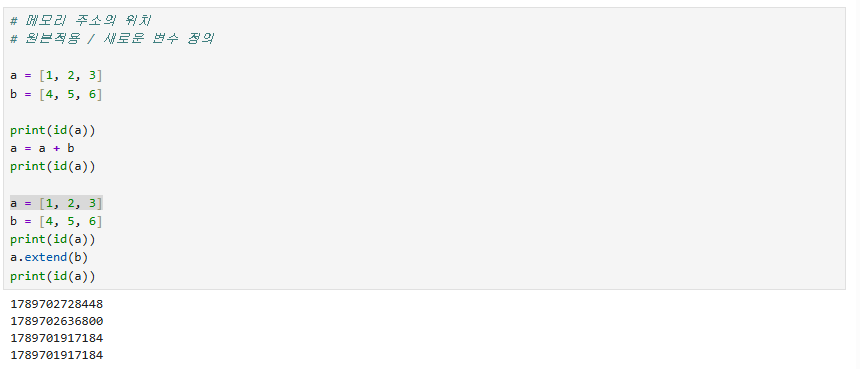
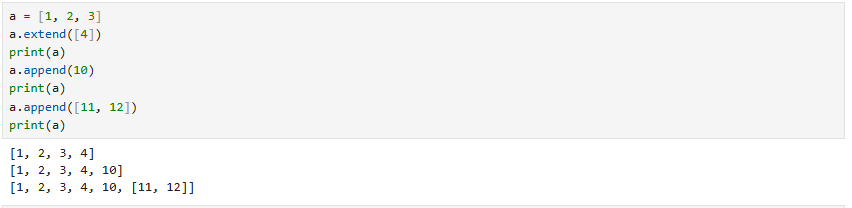
extend는 해당 객체의 형식과 같게 삽입해 줘야 한다.
하지만 append는 리스트에 리스트를 넣는 것처럼 2차원 배열이 되어버린다.
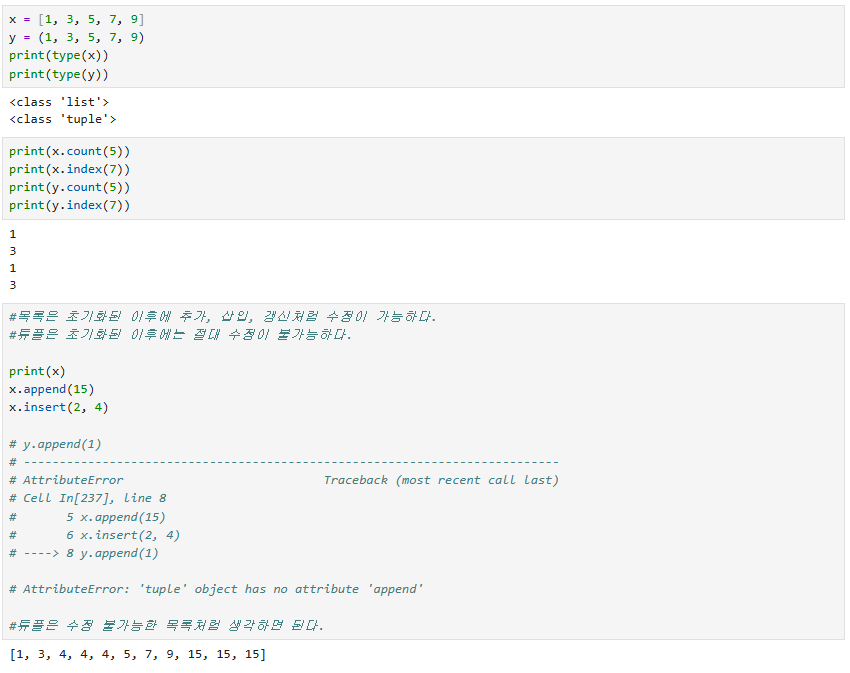
튜플은 대체로 리스트와 동일한 특성을 가진다.
final 상수처럼 선언과 동시에 수정이 불가능한 리스트라고 생각하면 될 것 같다.
사전형 자료형
key = value 형식으로 사전형으로 선언한 구조체이다.
임의 접근이라는 말처럼 순서의 중요성이 낮고 키값에 매핑된 value를 사용할 수 있는 방식이다.

이런 식으로 선언하면 목록형의 경우 고정된 인덱스를 사용할 수 없지만 키-값 형태인 사전형은 편하게 사용 가능하다.

사전형의 장점을 정확하게 보여준다.
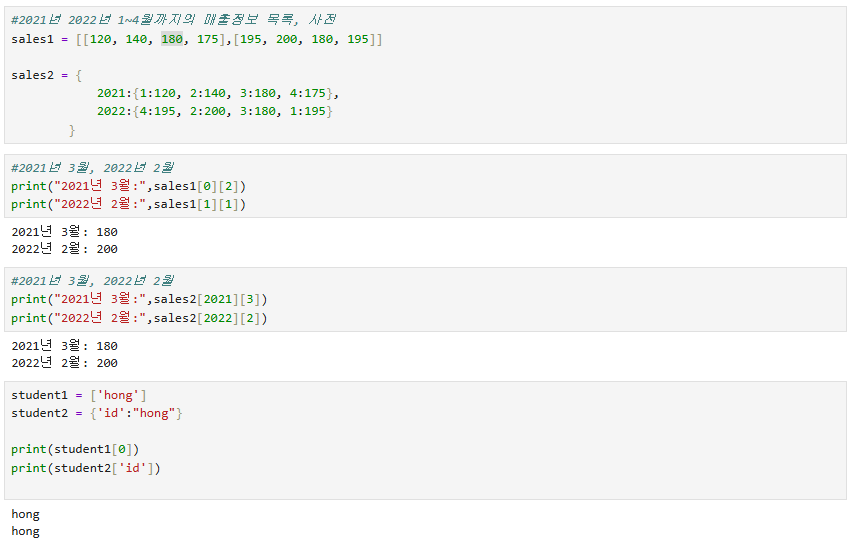
목록에서의 인덱싱과 사전형에서의 키에의한 인덱싱을 보여주는 예제이다.

목록형은 추가와 제거 혹은 수정이 이런 식으로 이루어진다.
사전형은 원래 있던 키값이 있다면 수정, 없다면 생성의 개념으로 진행된다.
하지만 키값은 유일해야 한다.
문법적으로 오류는 없겠지만 결국 1번 키가 3번 덮어쓰여져서 원하지 않는 결과가 나온 모습이다.
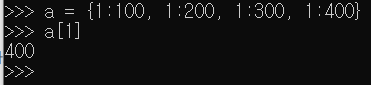
사전형에서 메서드로 keys(), values(), items()를 사용해서 키, 값, 아이템 등 원하는 값을 모아서 출력할 수 있다.

일반적으로 사전형 데이터 목록에 없는 데이터에 접근하면 keyError가 생긴다.
이때 키 에러를 막기 위해서 get메서드를 사용하면 되는데 get 메서드는 없는 데이터에 접근해도
None이라는 값을 반환하고 error를 출력하지 않는다.
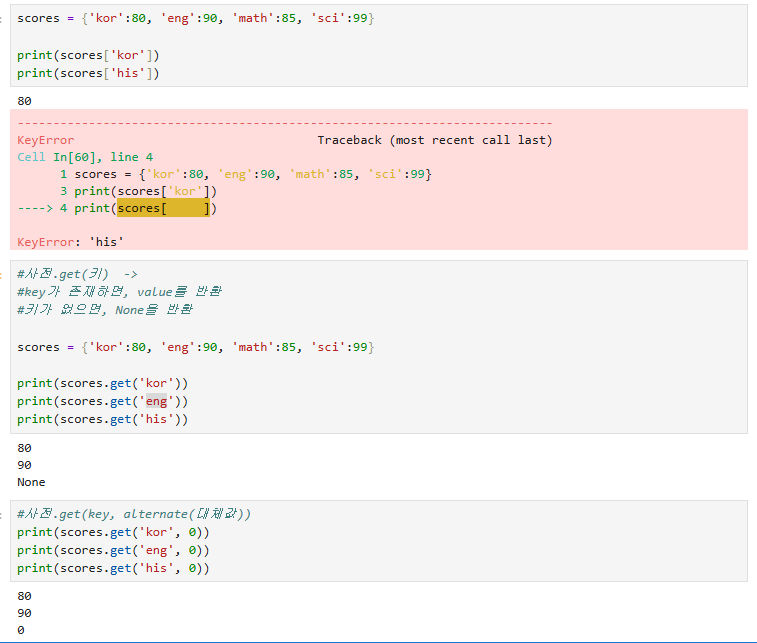
이렇게 get 메서드에 0인자값을 넣어주면 없을 시 0을 출력해 준다.
기본값은 none인 것을 알 수 있다.
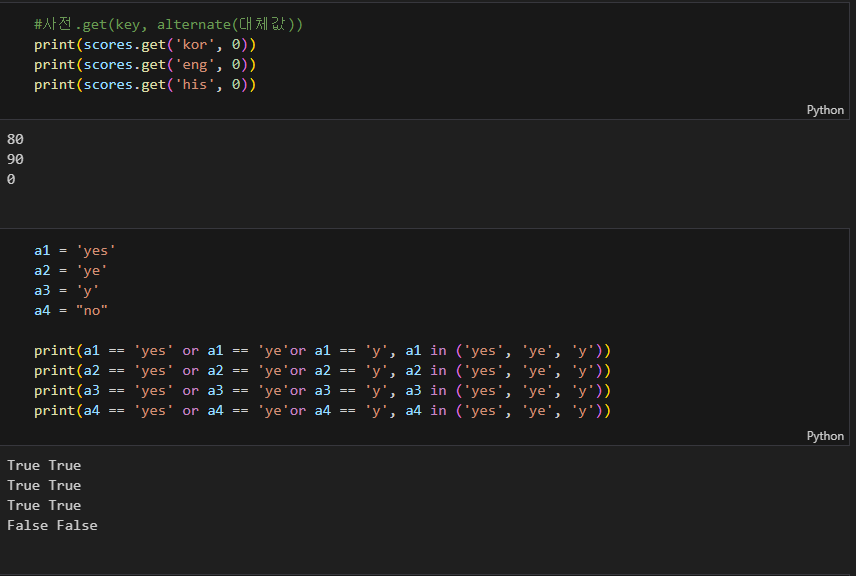
이 바로 위 사진인 값을, in을 사용하지 않고 인자를 찾으려면 많은 논리연산이 필요해진다.
in 뒤에는 목록, 튜플 등 안에 찾을 수 있는지 확인을 해준다.
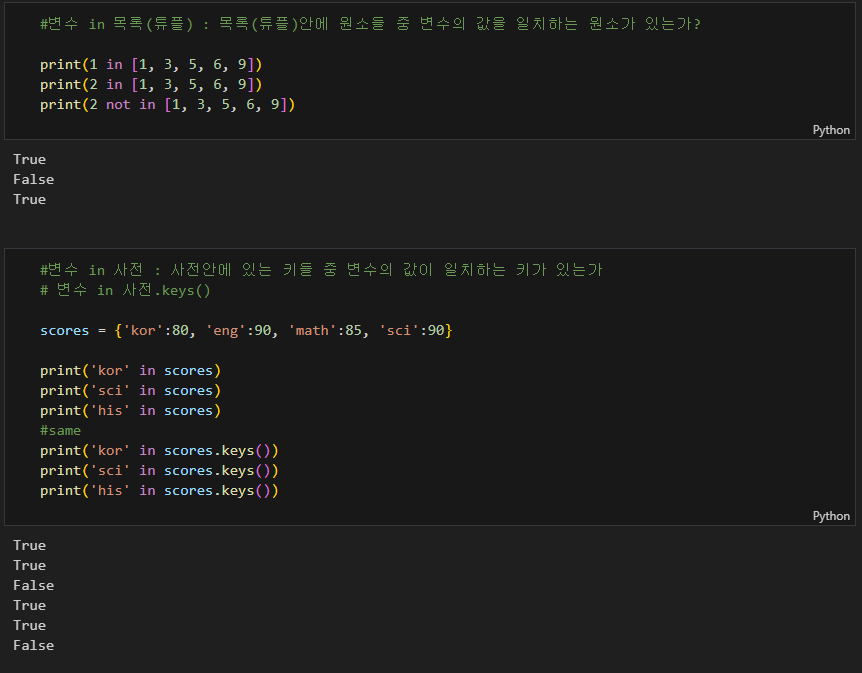
requests 모듈을 이용하여 html 문서를 확인해 보자
아마 저 response의 타입을 확인하면 클래스일 것이다.
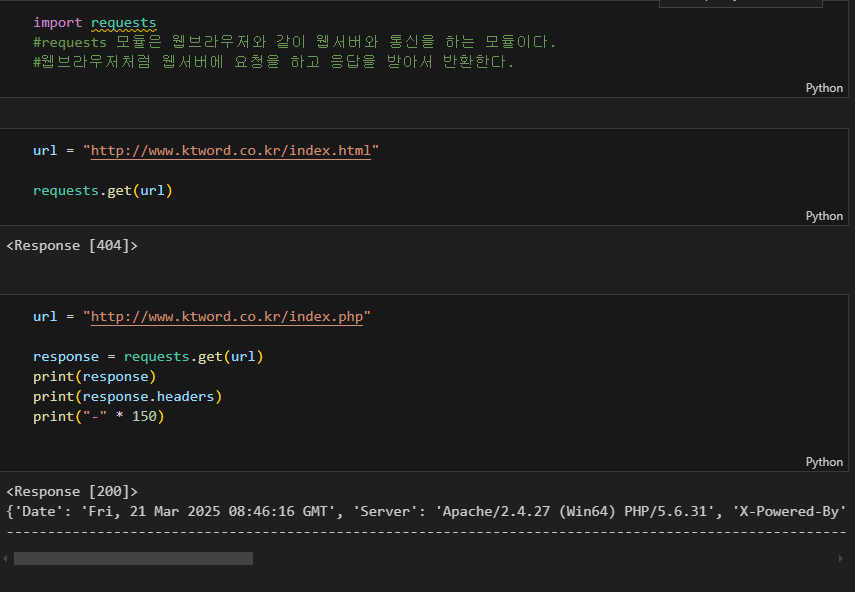
content.decode() 메서드는 html 문서를 보기 편하게 해독해 준다.

text로 적어도 해독해 주긴 한다.
슬라이싱으로 전부 출력하지 않고 100자까지만 출력해 주자
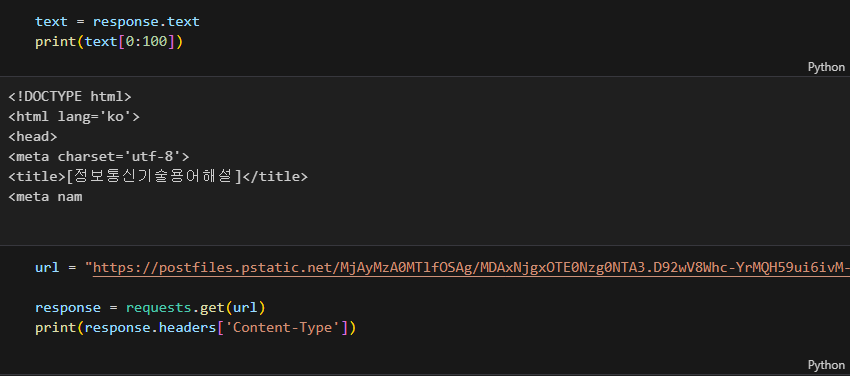
이미지를 받아오면 작업 디렉토리에 이미지가 받아봐질 것이다.
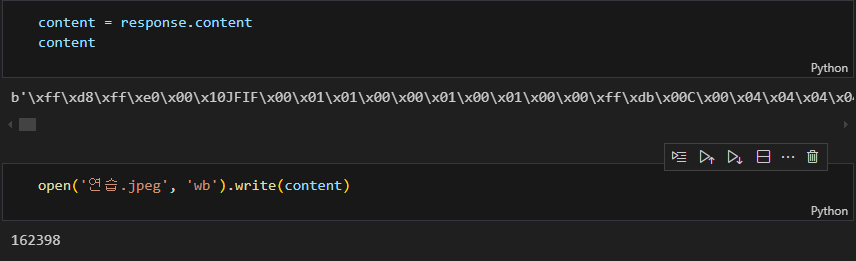
잘 받아와졌다.

'클라우드 국비 과정 > python' 카테고리의 다른 글
| 파이썬 강의 4일차_2025_03_28 (0) | 2025.03.28 |
|---|---|
| 파이썬 강의 3일차_2025_03_27 (0) | 2025.03.27 |
| 파이썬 강의 1일차_2025_03_20 (0) | 2025.03.20 |
- Total
- Today
- Yesterday
- 추가변수
- mariaDB
- named.conf
- JOIN
- Database
- 캐싱네임서버
- GROUP BY
- 방화벽
- 그룹변수
- 앤서블
- TCP
- ansible
- Lan
- zon
- 서브네팅
- destination /etc not writable
- OSI 7계층
- 호스트변수
- CCNA 1년 도전기
- IP
- 프로토콜
- getsebool
- tar
- 플레이변수
- WordPress
- OSI
- permission
- dns
- DBMS
- WAN
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |